La estructura en las redes personales
Christopher McCarty – Bureau of Economics and Business Research, Universidad de Florida[1]
Resumen
La mayoría de los estudios de redes personales (egocéntricas) describen las redes utilizando medidas que no son estructurales, recurriendo en su lugar a análisis de base-atributiva que resumen las relaciones de los encuestados con los miembros de la red. Los investigadores que han utilizado medidas estructurales lo han hecho con redes de menos de 10 miembros, que representan el núcleo de la red. Aunque se ha aprendido mucho centrándose en el análisis atributivo de los datos de redes personales, la aplicación de los análisis estructurales que tradicionalmente se han aplicado con datos de redes completas (sociocéntricas) puede resultar provechoso. La utilidad de este enfoque resulta evidente cuando la muestra elicitada de miembros de la red es relativamente grande.
Cuarenta seis encuestados hicieron una lista libre de 60 miembros de la red y evaluaron la fuerza del lazo entre 1.770 pares de miembros. Los indicadores basados en grafos de de cohesión y subgrupos revelaron la variabilidad de la estructura de las redes personales. El análisis de clusters no jerárquicos generó subgrupos que fueron verificados a continuación por los encuestados como significativos. Posteriores análisis de la correlación entre los tipos de subgrupos y el solapamiento entre subgrupos demuestra cómo el análisis de cada red puede resumirse entre sujetos. Se presentan cuatro estudios de caso para ilustrar la riqueza de los datos y el valor de contrastar los resultados de la matriz individual con la norma definida por los 45 sujetos.
Palabras clave: Red personal – Red egocéntrica – Estructura de la red social.
Abstract
Most personal (egocentric) network studies describe networks using measures that are not structural, opting instead for attribute-based analyses that summarize the relationships of the respondent to network members. Those researchers that used structural measures have done so on networks of less than 10 members who represent the network core. Although much has been learned by focusing on attribute-based analyses of personal network data, the application of structural analyses that are traditionally used on whole (sociocentric) network data may prove fruitful. The utility of this approach becomes apparent when the sample of network members elicited is relatively large.
Forty-six respondents free-listed 60 network members and evaluated tie strength between all 1,770 unique pairs of members. Graph-based measures of cohesion and subgroups revealed variability in the personal network structure. Non-hierarchical clustering generated subgroups that were subsequently verified by respondents as meaningful. Further analysis of the correlation between subgroup types and overlap between subgroups demonstrates how the analysis of each network can be summarized across subjects. Four case studies are presented to illustrate the richness of the data and the value of contrasting individual matrix results to the norm as defined by all 45 subjects.
Key words: Personal network – Egocentric network – Social network structure.
Introducción
Los estudios de redes personales (egocéntricas) se centran en las relaciones sociales de los individuos. Habitualmente los investigadores elicitan los nombres de familiares, amigos y conocidos de los encuestados que no tienen relación entre sí. Estos datos se analizan resumiendo las características de los miembros de la red para cada encuestado y correlacionando las características agregadas con las características individuales de los propios encuestados. Este tipo de datos permite a los investigadores estudiar cosas tales como las características de las redes de apoyo social (Wellman & Wortley, 1990), las variaciones en el apoyo social tras un desastre natural (Beggs, Haines & Hurlbert, 1996), la influencia de las redes en el comportamiento de llevar pistola entre los adolescentes negros (Myers et al., 1997), la relación entre el uso de drogas intravenosas y la transmisión del VIH (Neaigus et al., 1994), o el efecto de las redes personales en el comportamiento de voto (Nieuwbeerta & Flap, 2000).
En contraste, los que estudian redes completas (sociocéntricas) están interesados en los patrones de relaciones entre encuestados que forman un grupo social definido. El grupo pueden ser los miembros de un club, una clase escolar o el comité ejecutivo de una empresa en el ranking Fortune 500. Los que estudian redes completas miden la fuerza del lazo entre todos los miembros del grupo, y con eso disponen de una matriz de proximidades que representa los patrones de relaciones. Aplican un conjunto de técnicas de análisis basadas en matrices, algunas de ellas exclusivas del análisis de redes sociales (tales como la centralidad y la densidad), y otras que son habitualmente usadas en la estadística multivariante (tales como el análisis de clusters y el escalamiento multi-dimensional). Los investigadores que siguen el enfoque de redes completas examinan temas tales como la formación del estado en la Italia del Renacimiento (Padgett & Ansell, 1993), la estructura de las redes corporativas japonesas (Gerlach, 1992), o la innovación empresarial (Raider, 1998).
Entre los investigadores de redes sociales se asume con frecuencia que la aplicación de los análisis típicos de las redes completas no puede extenderse a las redes personales. Según parece, con algunas excepciones, no hay razones matemáticas o estadísticas que impidan la aplicación de las técnicas matriciales a los datos de redes personales. Hay, sin embargo, limitaciones conceptuales y logísticas.
En primer lugar, generar matrices de datos para encuestados individuales consume mucho tiempo y es potencialmente caro. Los datos sobre las redes personales de los encuestados son generados por los propios encuestados, de forma que ellos mismos tienen que evaluar la fuerza del lazo entre cada par de miembros de la red. Para una red con un tamaño de 50 personas esto supone 1.225 pares. Para una red de 100 personas supone 4.950 parejas.
Aunque se trata de una tarea tediosa, generalmente la evaluación individual es fácil de hacer. La gente tiende a clasificar a los miembros de la red en grupos y es frecuente que los miembros de un grupo no conozcan a los miembros de otro. Por ejemplo, no es raro que no haya lazos entre la familia y los compañeros de trabajo. La evaluación de los lazos entre dichos miembros lleva poco tiempo, especialmente cuando la evaluación se centra en la presencia o ausencia del lazo, y no en la fuerza del mismo. Este estudio mostrará que los encuestados pueden hacer las evaluaciones en un tiempo razonable y, en la mayoría de los casos, con poco cansancio.
El segundo obstáculo es un tema relacionado, el supuesto básico de que un encuestado puede informar con fiabilidad sobre los miembros de su red. Muchos investigadores de redes cuestionan la fiabilidad de los encuestados sobre sus lazos con otros, por no mencionar su información sobre los lazos entre los miembros de la red. Los críticos dirían que en el mejor de los casos estamos trabajando con la percepción de relaciones, más que con relaciones de hecho.
Se ha escrito mucho sobre el valor de medir la percepción social frente a las relaciones observables (véase Mayhew, 1981), y no vamos a resolver el debate aquí. Mi opinión es que al menos una parte del comportamiento está guiado por las percepciones del entorno, físico o social, y que el informe de los encuestados sobre los lazos refleja el ambiente social. Además, creo que los encuestados pueden informar con fiabilidad sobre las relaciones entre los miembros de la red, especialmente cuando sólo informan de la presencia o la ausencia de una relación. Una vez más este estudio mostrará que las estructuras derivadas de los datos de redes personales son significativas para los encuestados, prestando apoyo a la idea de que su evaluación de lazos sociales es fiable.
Por último, en un estudio de redes completas la meta consiste en obtener una estructura, contribuyendo cada miembro de la red igualmente a dicha estructura. Algunos miembros de la red serán más centrales que otros gracias a la contribución de todos los miembros de la red. Quien es ajeno al grupo contribuye a la definición de una posición más central de otro miembro de la red.
En contraste, el enfoque de redes personales está diseñado para determinar la influencia de cada miembro de la red sobre el encuestado. Este enfoque se basa en el hecho de que cada miembro de la red no contribuye igualmente a la personalidad y el comportamiento del encuestado. La aproximación matricial asume sin embargo que todos los miembros de la red contribuyen del mismo modo a la estructura. Los compañeros de trabajo de Ego contribuyen tanto a las propiedades estructurales de la red como la madre de Ego. Un análisis estructural no dará cuenta de la contribución singular de un solo miembro de la red. Sin embargo sí podemos observar cómo los atributos de los miembros de la red se asocian con la estructura.
Los datos típicos de redes personales
Campbell & Lee (1991) y McCarty et al. (1997) resumen los tipos de datos que se recogen en los estudios de redes personales. Casi todas las medidas compiladas de los datos son resúmenes de atributos de los miembros de la red que luego se comparan con los mismos (u otros) atributos de los encuestados. Es frecuente que se recojan variables sociodemográficas de los miembros de la red, tales como la edad, el sexo, y el grupo étnico, y luego dichas variables se resumen como promedios y porcentajes. Por ejemplo, se podría comparar el promedio de edad de los miembros de la red, viendo cómo varía en función de la edad de los encuestados.
Otras preguntas habituales que se hacen a los encuestados se refieren al tipo o al contenido de la relación que los entrevistados tienen con cada miembro de la red. Las relaciones pueden clasificarse en función de los tipos de cosas que el encuestado espera que los miembros de la red hagan (Bernard et al., 1990) o una clasificación de las relaciones dentro de un esquema definido (Fischer, 1982; Bernard et al., 1988; McCarty et al., 1997). En todos los casos las categorías de las relaciones son creadas por el investigador.
Casi todos los investigadores de redes personales recogen algún tipo de medida sobre la fortaleza del lazo, es decir, lo cerca que se encuentra el encuestado de cada miembro que previamente ha listado. Las preguntas pueden ser muy explícitas, tales como “¿con qué frecuencia ves a X?” o “¿cuánto tiempo hace que conoces a X?”. Las preguntas pueden ser también más abstractas, tales como “¿cuánto conoces a X?” (McCarty, 1996, Marsden & Campbell, 1984).
Todos estos datos son atributos de los miembros de la red, y hasta ahora los atributos no han sido utilizados para estudiar la estructura. Sería posible analizar la estructura de la red a través de los atributos de los miembros de la red utilizando las diferencias entre atributos como una aproximación a la similitud y la disimilaridad. Podríamos aproximarnos a un lazo entre dos miembros de la red por su similitud en terminado atributo, tales como el grupo étnico, el sexo, la edad o una combinación de las mismas. Es indiscutible que la estructura obtenida a través de dichas definiciones tendría un aspecto muy diferente de la estructura obtenida a través de las evaluaciones que hacen los encuestados de los lazos entre los miembros de la red.
Por estas razones los investigadores de redes personales habitualmente no les piden a los encuestados que evalúen la existencia de un lazo entre los miembros de la red. Aquellos que han planteado dichas preguntas las limitan a un pequeño conjunto de miembros del núcleo de la red que, como miembros del núcleo, es frecuente que tengan un alto grado de interacción. Por causa de esta estrecha interacción, el análisis de la estructura entre los miembros del núcleo de la red demuestra poca varianza entre encuestados (Marsden, 1990).
Como he dicho, el estudio que presentamos aquí no es el primer intento de aplicar medidas estructurales a los datos de redes personales. La densidad de la red ha sido medida en varios estudios de redes personales (véase Wellman, 1979; Fischer, 1982; Burt, 1984; Campbell & Lee, 1991; Volker, 2001). La diferencia entre estudios anteriores y el que se presenta aquí tiene que ver sólo con un número más amplio de miembros de la red y la adición de la evaluación de los lazos entre cada miembro. Con un relativamente pequeño número de miembros de la red que tienden a ser amigos íntimos y familiares, hay muy poca variación estructural que explicar. Cuando el monto de relaciones potenciales se amplía para incluir muchos tipos de miembros de la red, tanto conocidos como amigos, se revela una estructura con un aspecto diferente. Y para muchos comportamientos esperaríamos que los efectos de la estructura vengan de lazos indirectos así como de lazos que son íntimos y más directos (Walker, Wasserman & Wellman, 1993; Gottlieb, 1981; Wellman, 1981).
El trabajo más riguroso de la estructura en las redes personales es el de Burt y su trabajo sobre los agujeros estructurales (1992). Burt utiliza su propia medida de redundancia en las redes personales como una aproximación a la variación en las “oportunidades de intermediación”. Entonces pone en relación dicha variación con variables de nivel del encuestado tales como la personalidad (1998), o el poder y la movilidad en una red corporativa. Burt ha acumulado una amplia base de datos de redes de ego de managers que oscilan entre 6 y 20 alteri, que usa como un banco de pruebas para la consultoría empresarial. Mientras que algunos investigadores han escrito sobre el concepto de agujeros estructurales (Krackhardt, 1999) o temas relacionados con su medición (Borgatti, 1997), muy pocos han recogido de hecho datos de redes personales y aplicado los conceptos de Burt, y ninguno, incluyendo a Burt, lo han hecho fuera del contexto de los negocios.
Quizás el ejemplo más cercano a lo que estoy intentando realizar con este artículo se encuentra en el análisis de Mitchell de las redes de apoyo social de las mujeres sin hogar en Manchester (Mitchell, 1994). Los datos del análisis de Mitchell se derivan de un estudio de los 1970s de las personas sin hogar. En unos pocos casos Mitchell y sus colegas pidieron a los encuestados que evaluaran la fuerza del lazo entre los 20 alteri de sus redes de apoyo. Mitchell presenta varios análisis utilizando CONCOR, y representa la estructura de las redes personales resultantes. Claramente la estructura de las redes personales ofrece algunas explicaciones añadidas a la forma en la que funciona la red de apoyo de los encuestados, más allá de los análisis de atributos típicos de la mayoría de los estudios de redes personales.
Spreen (1992, 1999) y Spreen & Zwaagstra (1994) han desarrollado métodos para estimar estructuras de las redes personales utilizando datos muestrales. Su investigación es parte de un esfuerzo para obtener la estructura de grandes redes completas, especialmente la de poblaciones ocultas o escurridizas tales como los usuarios de heroína. Esta tradición, de la que es pionero Frank (1978), se basa en el muestreo de bola de nieve a partir de miembros conocidos de dichas poblaciones para estimar las características estructurales de las redes completas. Estos esfuerzos de investigación se han centrado en estimar la estructura de grandes redes completas en las que las fronteras son desconocidas, y no en la descripción o el análisis de la estructura de las redes personales por sí mismas.
Los datos
Estos datos se originan en un estudio de la percepción de subgrupos en las redes personales que son consecuencia de preguntas sobre la validez de las categorías de relación utilizadas en la investigación de las redes personales. Habitualmente los investigadores crean categorías y luego preguntan a los encuestados cuál es la categoría que mejor describe su lazo con el miembro de la red (por ejemplo, familia, colega, afiliación religiosa). El propósito de esta investigación fue disponer de una lista libre de nombres de miembros de la red de los encuestados, y evaluar los lazos entre todos los miembros. El objetivo fue crear clusters basados en las interacciones percibidas de los miembros de la red, lo cual podría revelar sesgos en las categorías de relaciones preconcebidas que con frecuencia se utilizan en la investigación de redes personales.
Cuarenta y seis encuestados fueron reclutados a través de amigos y anuncios en prensa. Se pidió a los encuestados que hicieran un “listado de 60 personas a las que conoces –es decir, gente que está viva, a la que puedes reconocer por la vista o por el nombre, que te reconocen por la vista o por el nombre, y con la que puedes contactar si lo necesitas”. No se les dio a los encuestados ejemplos de los tipos de persona que podían incluir, pero se les permitió utilizar pseudónimos si no podían recordar el nombre exacto. Los 46 encuestados produjeron 2.760 nombres. Después de nombrar 60 alteri, los encuestados indicaron cuánto conocían a cada uno (en una escala de 1 a 5, en la que 1 era “no lo conozco muy bien” y 5 era “lo conozco muy bien”).
A continuación describieron, en sus propias palabras, cómo conocieron a cada alter (“es mi hermana”, “es la hija de mi profesor”, “es mi antiguo jefe”, “es el batería en la banda de mi amigo”, “es la exnovia de mi exnovio”). A los encuestados también se les mostró una lista de 23 formas en las que la gente se conoce entre sí y se les pidió que señalaran hasta tres de los modos en los que conocieron a cada uno de sus 60 miembros.
Por último, se mostró a los encuestados cada una de las 1.770 parejas de sus 60 miembros y se les preguntó, respecto a cada par: “¿Se conocen estas dos personas entre sí y, de ser así, en una escala de 0 a 5, cuánto se conocen?” donde 0 era “no se conocen”. Esta parte del ejercicio de recolección de datos llevó 45 minutos en promedio. Para comprobar la fiabilidad de este procedimiento, los encuestados codificaron cada pareja número 59 en una segunda ocasión. Para estos 30 pares, el 93% fue codificado de forma idéntica la segunda vez, y el 97% señaló que se conocían entre sí con una escala de ±1 respecto a la codificación original.
Análisis estructural utilizando medidas basadas en grafos
A diferencia de los indicadores estadísticos, tales como el escalamiento multidimensional y el análisis de cluster, muchas medidas basadas en grafos dependen de la presencia o ausencia de lazos entre alteri e ignoran la fuerza del lazo. Para utilizar estas medidas los datos tienen que ser recodificados. Es decir, si un encuestado evaluó el lazo entre dos alteri como mayor o igual a 1 se codificó como 1, de lo contrario se calificó como 0.
También debo señalar que para estos análisis Ego fue eliminado de la matriz de proximidades. El argumento para prescindir de Ego es que las medidas estructurales, tales como la centralidad o los cliques, mostrarían una muy alta cohesión puesto que Ego, por definición, conoce y está conectado con todo el mundo. Aún puede haber variabilidad, pero mucho menos. El argumento en contra de la eliminación de Ego es que en cierto sentido ya no es una red definida. En el mejor de los casos la estructura refleja el potencial de los alteri para transmitir información sobre Ego entre sí cuando Ego no está presente. Los dos enfoques tienen mérito.
A continuación proporciona las definiciones de 6 medidas basadas en grafo que fueron calculadas para las 46 matrices de proximidades. El resumen de los indicadores está disponible en la Tabla 1.
Densidad. El porcentaje de lazos que existen en una red de entre el total de lazos posibles. Una densidad de 1.0 implica que cada alter está conectado con todos los demás. Una densidad de 0 significa que ningún alter conoce a ningún otro.
Grado de centralidad (degree). Es una medida de actividad en la red. Un alter tiene una alta centralidad de grado en la medida en que está directamente conectado a muchos otros alteri. Un grafo (una red) tiene una alta centralidad de grado en la medida en la que hay una amplia variabilidad del punto de centralidad de grado entre los alteri. Una red en estrella, en la que un alter es el intermediario para todos los alteri, estaría centralizada en un 100%. Una red en la que todos los alteri tienen el mismo número de lazos en la red sería un grafo con una centralidad de grado de 0. El grado de centralidad es una medida de los lazos directos, y por tanto debería utilizarse para conceptos que requieran de lazos directos.
Cercanía (closeness). Es una medida de la independencia respecto al control de otros. Es un concepto similar al de centralidad de grado, excepto que se centra en el camino y no sólo en los lazos directos, de forma que un alter se considera conectado (alcanzable) a través de intermediarios. Un alter tiene una elevada cercanía si está conectado a través de caminos cortos con muchos otros alteri. Como la centralidad de grado, un 100% de centralización implica una red en estrella y 0 significa que todos los alteri tienen el mismo número de lazos. La centralidad de cercanía en una red personal sería una medida útil cuando el concepto estudiado no requiera de un lazo directo.
Intermediación (betweenness). Una medida del control de información. Un alter tiene una alto nivel de betweeness en la medida en que se ubica en muchos geodésicos (los caminos más cortos) entre alteri. En ese sentido actúan como puente entre alteri, y potencialmente controlan la información. De nuevo, la centralización del 100% de toda la red implica que un alter es el puente para todos los demás, como la estrella en red, y una centralización betweeness de 0 implica que ningún alter es puente para ningún otro, como ocurre en un grafo en círculo.
Cliques. Una clique en una red personal es un conjunto de alteri que están directamente enlazados entre sí. Puede haber solapamiento entre cliques, es decir un alter puede ser miembro de más de una clique. Puesto que las cliques son grafos completos máximos, no se puede hacer una clique con un subconjunto de miembros de una claque. Por lo tanto el número de cliques que existen en un grafo es una medida del número de subgrupos que existen.
Componentes. Un componente en una red personal es un conjunto de alteri que están conectados entre sí directa o indirectamente. A diferencia de una clique, los miembros de un componente no tienen por qué estar conectados con todos los demás en el subgrupo. Si hay un camino hasta un alter, será un miembro del componente. Una red con muchos componentes implica una red compartimentalizada.
Todas las medidas listadas en la Tabla 1 son sensibles al número de alteri en la red. Puesto que se solicitó a los encuestados que listaran exactamente 60 alteri, las medidas en la Tabla 1 son comparables. Esto subraya el valor de restringir la elicitación de la red personal a un mismo número de alteri cuando se trata de hacer comparaciones estructurales.
También es importante señalar que para la centralidad hay tanto indicadores que calculan la centralidad de cada nodo como indicadores que estiman el nivel de centralidad en el grafo completo. En cada red personal un alter es habitualmente el más central en el grafo. Son los alteri con un punto de centralidad más elevado. Freeman (1979) discute métodos para calcular la centralidad del grafo completo también. Las Tablas 1 y 2 se basan en la centralidad global de la red completa mientras que la Tabla 3 se basa en el punto de centralidad de cada alter en la red.
|
Medida |
Qué mide |
Medida |
Min. |
Max. |
Desviación tipo |
Coeficiente de variación |
|
Densidad |
Lazos |
0.24 |
.11 |
.56 |
0.09 |
36.32 |
|
Grado (Degree) |
Cohesión |
46.05 |
19.18 |
80.07 |
17.27 |
37.51 |
|
Cercanía (Closeness) |
Cohesión |
33.60 |
0.44 |
84.7 |
25.11 |
74.73 |
|
Intermediación (Betweenness) |
Cohesión |
29.18 |
1.65 |
57.8 |
14.26 |
48.88 |
|
Cliques |
Subgrupos |
74.30 |
21 |
204 |
39.41 |
53.04 |
|
Componentes |
Subgrupos |
1.93 |
1 |
6 |
1.25 |
64.83 |
Tabla 1. Valores promedio de seis medidas basadas en grafos
Lo primero que resulta evidente en la Tabla 1 es que la estructura de las redes personales varía. Por ejemplo, la centralidad de cercanía (closeness) oscila entre 0.44 y 84.7, cuando el rango posible es de 0 a 100. El coeficiente de variación (la desviación tipo dividida por la media) indica que de las seis medidas, la cercanía (closeness) es la que más varía entre los 46 encuestados.
La Tabla 2 muestra la relación entre estas medidas de grafos. Casi la mitad de los indicadores correlacionan significativamente entre sí. Examinando cómo estas medidas se relacionan entre sí se hace más claro lo que significan y cómo podrían aplicarse en el análisis de redes. Por ejemplo, hay una fuerte asociación negativa entre los componentes y la densidad. Esto es así porque en una red muy densa la gente tiende a estar conectada con los demás a través de por lo menos un camino, reduciendo el número de componentes independientes. De un modo similar, en una red muy densa hay potencialmente mucha gente conectada entre sí, lo cual lleva a una cercanía baja (closeness), resultando en una fuerte correlación negativa. Por el contrario, una red muy densa crea oportunidades para la existencia de muchos subgrupos en los que todos se conocen entre sí (cliques), resultando en una correlación positiva entre la densidad de la red y el número de cliques.
La correlación entre densidad y grado no es significativa. Teniendo en cuenta que la centralidad de grado se centra en lazos directos, como en el caso de la densidad de la red, esto puede resultar sorprendente. Sin embargo, la densidad es simplemente una medida de los lazos en toda la red mientras que la centralidad es una medida de la cohesión en la red. Esto apunta al valor de las puntuaciones de centralidad y las limitaciones de la densidad de la red como medidas de cohesión.
|
|
Densidad |
Grado |
Cercanía |
Betweeness |
Cliques |
Componentes |
|
Densidad |
|
.07(.632) |
.41(.005) |
-.41(.005) |
.49(.001) |
-.45(.002) |
|
Grado |
|
|
.56(.001) |
-.30(.042) |
.12(.425) |
-.29(.053) |
|
Cercanía |
|
|
|
.27(.065) |
.22(.139) |
-.72(.001) |
|
Between. |
|
|
|
|
.30(.042) |
.07(.623) |
|
Cliques |
|
|
|
|
|
-.22(.131) |
|
Compon. |
|
|
|
|
|
|
Tabla 2. Correlación de los indicadores basados en grafos – Valor (Prob. > r)
El análisis anterior muestra que la centralidad general del grafo varía significativamente entre las redes personales de los encuestados, y que los tres tipos de centralidad (grado, cercanía e intermediación) se centran en diferentes aspectos de la red, especialmente el indicador de betweeness. La Tabla 3 se basa en el análisis del alter más central en cada red para cada tipo de centralidad. La última fila muestra que el 44% de los encuestados tienen al mismo alter como el más central para los tres tipos de centralidad. En contraste, el 11% tiene un alter diferente para cada tipo de centralidad. Una explicación de los diferentes patrones existentes en dichas redes es la separación geográfica de los alters. Entre aquellos encuestados en los que hay un alter para cada tipo de centralidad, en promedio casi la mitad son del mismo lugar fuera del Estado de Florida (donde se recogieron los datos), en comparación con menos de un tercio para aquellos en los que el mismo alter fue el más central para las tres medidas.
|
Close – Degree |
Close - Between |
Degree – Between |
Porcentaje |
|
No |
No |
No |
11 |
|
No |
No |
Sí |
15 |
|
No |
Sí |
No |
15 |
|
Sí |
No |
No |
15 |
|
Sí |
Sí |
Sí |
44 |
|
TOTAL |
100 |
||
Tabla 3. Distribución de diferentes tipos de centralidad, mostrando si el alter más central para cada par de medidas de centralidad es el mismo.
La tabla indica la medida en la que los encuestados identificaron al mismo individuo como el más destacado en cada par de medidas de centralidad. Por ejemplo, un “No” en la columna “Close-Degree” indica que el encuestado no identificó al mismo alter como el de mayor puntuación en cercanía y en grado; un “Sí” en la columna “Close-Degree” indica que el encuestado sí identificó al mismo alter como el de mayor puntuación tanto en cercanía como en grado. La columna final indica qué porcentaje de encuestados mostraron dicho patrón en centralidad.
Merece la pena señalar que la distribución de la Tabla 3 se basa en sólo 46 encuestados. El 44% de la muestra con el mismo alter en los tres indicadores de centralidad respresenta sólo 21 encuestados. Mientras que no debería sorprender que el patrón modal tenga el mismo alter con la máxima centralidad en los tres indicadores, es más sorprendente que existan los demás.
Por otro lado, es posible que la distribución de la Tabla 3 no sea más que un artefacto estadístico. Después de todo, tiene que haber alguna distribución. El único estudio que se refiere a este tema es, de nuevo, el de Freeman (1979). Freeman calculó los 34 posibles grafos de 5 puntos. Sólo 21 podían utilizarse para calcular las 3 medidas de centralidad. En el estudio de Freeman todos los casos tenían al mismo alter como el más central en los tres indicadores de centralidad. En el presente estudio sólo 5 encuestados se corresponden con dicho caso.
Pese a que no hay ninguna razón para esperar que la distribución de las puntuaciones de centralidad en una muestra de redes personales se corresponda con la distribución del análisis de Freeman sobre todos los grafos posibles, merece la pena plantearse si en la Tabla 3 hay efectivamente un patrón o se trata de un artefacto. Hay dos diferencias principales entre este estudio y el de Freeman. Primero, las redes de Freeman tienen 5 nodos mientras que estas tienen 60. Segundo, las redes de Freeman son obligadamente todas las configuraciones posibles, mientras que estas son redes reales. El lector puede apreciar que en general las comparaciones de las propiedades estructurales entre redes se han limitado en gran medida a modelos y datos conceptuales, debido a que apenas existen datos estructurales de las redes personales mientras que los análisis sociocéntricos suelen limitarse a una sola red.
Las entrevistas de estudios posteriores utilizando un formato similar sugieren que la estructura de las redes personales puede reflejar diferentes estrategias con las redes. Algunas personas tienden a compartimentalizar los alteri de su red, intentando conscientemente mantenerlos separados en grupos, mientras que otros tratan de reunir a las personas tanto como les sea posible. Es fácil imaginar las consecuencias de dichas estrategias en términos de flujo de la información, control y apoyo social, de forma que explorar esta variabilidad, quizás con inventarios de personalidad, pueda ser un área productiva de investigación.
Análisis de conglomerados
El análisis estadístico aprovecha la variabilidad en la fortaleza del lazo. Por eso se utilizaron las evaluaciones de lazos en bruto para las 46 matrices sometidas al análisis de cluster. Sin embargo, para asegurar que los grupos se formasen a partir de lazos realmente existentes, las matrices fueron recodificadas a datos binarios en los que un lazo de 4 o 5 fue recodificado como 1 y todos los demás como 0. Estas matrices fueron sometidas a continuación a análisis de cluster para buscar subgrupos basados en la percepción de los encuestados sobre la fuerza del lazo (en lugar de en categorías preconcebidas de relación). Una de las descripciones de los encuestados se basó en descripciones tan poco variables (“alguien que conocí en un club nocturno”) que su matriz no fue incluida en estos análisis.
Los conglomerados se calcularon utilizando análisis de cluster no jerárquico, en lugar del análisis jerárquico. Con este último los miembros sólo pueden pertenecer a un cluster. Con el análisis de cluster no jerárquico, los miembros pueden pertenecer a más de un conglomerado (Arabie et al., 1981). Como está implementado en el Sistema de Análisis Estadístico (SAS), el procedimiento ADCLUS requiere que el usuario especifique un número máximo de clusters. Después de algunos intentos de prueba, se producía un descenso en la varianza explicada para la mayoría de los encuestados después de extraer 14 clusters. Finalmente el punto de corte para el número de clusters se estableció en 14.
Interpretar los conglomerados es un ejercicio subjetivo. Utilizando la información que los encuestados dieron sobre cada miembro de la red, intenté determinar por qué los miembros del cluster se conocían entre sí. Incluso pese a que este proceso permitía mayor variabilidad en los tipos de cluster que en la mayoría de la investigación sobre redes personales, era evidente que se podrían haber identificado otros clusters si yo hubiese preguntado a los encuestados por otros detalles sobre los miembros de su red. Como ocurre con cualquier entrevista cualitativa, la información es con frecuencia una función de la cantidad y la dirección de la prueba.
Después de codificar los 45 conjuntos de clusters, parecían existir 12 categorías principales, tres de las cuales fueron finalmente divididas generando un total de 19 tipos de conglomerados. La Tabla 4 muestra los tipos de cluster y el porcentaje de encuestados que tenían conglomerados correspondientes a cada categoría. Con hasta 14 clusters extraidos con ADCLUS para cada encuestado, podría haber hasta 14 de los 19 tipos de clusters representados en cada caso. Esto nunca ocurrió. El número mínimo de tipos de clusters fue 3 y el máximo fue 11. En promedio, los encuestados tenían 6.3 tipos de clusters (con una desviación tipo de 1.8).
|
Tipo de Cluster |
Frecuencia |
Porcentaje |
|
Familia |
45 |
100 |
|
--Materna |
6 |
13 |
|
--Paterna |
7 |
16 |
|
--Cercana o íntima |
32 |
71 |
|
--General |
28 |
62 |
|
--La familia de la pareja |
22 |
49 |
|
--Incluyendo amigos |
25 |
56 |
|
Red a través de otra persona |
25 |
56 |
|
Parejas |
23 |
51 |
|
Infancia, crecieron juntos |
4 |
9 |
|
Estudian juntos |
21 |
47 |
|
--Instituto |
5 |
11 |
|
--Universidad |
18 |
40 |
|
Trabajan juntos |
33 |
73 |
|
--Trabajo actual |
23 |
51 |
|
--Antiguo trabajo |
19 |
42 |
|
Compañeros de alojamiento |
3 |
7 |
|
Afiliación religiosa |
5 |
11 |
|
Grupo de hobbies |
6 |
13 |
|
Grupo orientado por un tema |
8 |
18 |
|
Vecinos |
13 |
29 |
|
Grupo social |
13 |
29 |
Tabla 4. Porcentaje de encuestados que tienen determinados tipos de clusters
Todos los encuestados tenían clusters compuestos por miembros de la familia. Para algunos encuestados los clusters familiares estaban claramente compuestos por la familia materna o bien por la paterna, y para casi la mitad de los encuestados (49%) había conglomerados compuestos por la familia del esposo (o de la pareja). Los encuestados que tenían conglomerados de la familia paterna tendían a no tenerlos de la familia materna, y viceversa. Seis encuestados tenían clusters de la familia materna y 7 de la paterna. Sólo dos encuestados tenían clusters de ambos tipos. Parece que entre los participantes en nuestro estudio se favorece (o se recuerda) una parte de la familia en detrimento de otra.
Hay un claro conjunto de clusters familiares basados en lo que los encuestados etiquetan como íntimos. En la mayoría de los casos es congruente con el nivel de conocimiento asignado por los encuestados a los miembros del cluster. He denominado a estos conglomerados familia cercana. La familia general incluye tanto a la familia cercana como a la más distante.
Más de la mitad de los encuestados (el 56%) tenía clusters cuyos miembros estaban vinculados a determinado intermediario. Los conglomerados a través de otras personas y los conglomerados compuestos por la pareja y su familia son tipos bastante vinculados. La mayoría de los clusters a través de terceros estaban compuestos por una pareja y su familia, como es el caso de una pareja y sus hijos. Habitualmente los encuestados eran más cercanos a un miembro de la pareja que a otro.
Veintiún encuestados (46%) tenían clusters compuestos por personas con las que habían estudiado. Concretamente el 40% estaba compuesto por miembros que conocieron en la universidad local, mientras que sólo el 11% de los encuestados tenían conglomerados de miembros conocidos en el Instituto.
Por último, había conglomerados compuestos por personas que compartían una afiliación religiosa o un hobby común, o que eran vecinos o compartían un grupo social, o que tenían un interés común. Ejemplos de este último tipo eran los conglomerados de personas que estaban en el mismo grupo terapeútico o grupo de encuentro, o que eran miembros de organizaciones políticas o reivindicativas. Estos clusters no eran mutuamente excluyentes. Los miembros podían estar en más de un tipo de cluster, es decir, en clusters solapados.
Para determinar la validez de los clusters, y especialmente para comprobar mi etiquetado, realizamos una prueba de fiabilidad con diez de los encuestados originales. A cada encuestado se le presentó una tarjeta que tenía (1) un cluster producido con sus propios datos, o bien (2) una tarjeta con uno de los siete clusters generados seleccionando números aleatorios entre 1 y 60 para completar clusters de 2, 4, 6, 8, 10, 12 y 14 miembros. Cada entrevistado vio siete clusters aleatorios (de tamaño 2, 4, etcétera) junto con los clusters generados con sus propios datos. Se les pidió que nombraran el grupo de gente de algún modo.
Todos los conglomerados formados por el procedimiento de análisis de cluster fueron identificados por los encuestados como un subgrupo intuitivamente claro. Además, describieron los contenidos de todos los clusters con etiquetas que coincidían con las mías. Sólo seis clusters aleatorios de un total de 70 fueron identificados por los entrevistados como significativos.
Correlación de los tipos de conglomerados
Es razonable asumir que hay tipos de cluster que suelen aparecer juntos mientras que otros no. La Tabla 5 muestra el resultado de un análisis de correlaciones de la presencia o la ausencia de tipos de clusters por encuestado. La primera fila indica que aquellos que se asocian con la familia de la pareja, muy probablemente el esposo, tienen más familia cercana para forma conglomerados de familia cercana. La correlación negativa entre familia cercana y familia general sugiere que hay una tendencia por la cual aquellos con familia cercana no tienen familia general, en lugar de tener ambos tipos. Hay una correlación negativa entre familia cercana y grupos de hobby.
|
Tipo de Cluster 1 |
Tipo de cluster 2 |
r de Pearson |
Probabilidad > r |
|
Familia cercana |
Familia de la pareja |
.43 |
.01 |
|
Antiguo trabajo |
Familia, incluyendo amigos |
-.32 |
.03 |
|
Hobby |
Orientado a un tema |
.33 |
.03 |
|
Hobby |
Familia cercana |
-.33 |
.03 |
|
Familia general |
Via red |
-.33 |
.03 |
|
Universidad |
Vecinos |
-.32 |
.03 |
|
Hobby |
Familia general |
.31 |
.04 |
|
Comparte vivienda |
Antiguo trabajo |
.31 |
.04 |
|
Familia general |
Religión |
-.31 |
.04 |
|
Instituto |
Antiguo trabajo |
-.30 |
.04 |
|
Orientado a un tema |
Vía red |
.30 |
.05 |
|
Familia cercana |
Familia general |
-.29 |
.05 |
|
Universidad |
Religión |
-.29 |
.05 |
|
Universidad |
Trabajo actual |
-.29 |
.05 |
|
Comparte vivienda |
Vía red |
-.30 |
.05 |
Tabla 5. Correlación de la presencia de tipos de clusters
Los grupos de la universidad se asocian negativamente con los vecinos, los grupos religiosos y el trabajo actual. Es menos problable que los estudiantes universitarios tengan trabajos a tiempo completo que los no estudiantes, o que estén muy implicados en los grupos de la iglesia. Dadas sus condiciones de vida, es menos probable que permanezcan en el mismo barrio durante años, y por tanto menos probable que formen grupos sociales con vecinos.
La asociación negativa entre los grupos del instituto y el antiguo trabajo está claramente relacionada con el tiempo. Aquellos que están lo suficientemente cerca del instituto como para mantener dichos grupos es menos probable que hayan tenido la experiencia de tener un anterior trabajo.
Un análisis factorial de esta matriz de correlaciones arrojó resultados muy similares. Quizás el resultado más revelador del análisis factorial fue el primer factor, en el que saturó la familia cercana en contra de la familia distante o general. En la investigación de redes personales hay una tendencia a clasificar los miembros de la red que son familiares juntos. Estos datos muestran que, entre estos encuestados, hay una distinción entre los miembros de la familia que puede ser tan importante como las distinciones entre miembros de la red basadas en la función de la relación.
Solapamiento
Hay pocos estudios que examinen el solapamiento en las redes personales. Algunos estudios de redes completas han descrito el solapamiento entre los miembros de la red y determinados acontecimientos (Galaskiewics & Marsden, 1978). Milardo (1989) estudió el salampamiento en las redes personales generadas a través de dos métodos diferentes, pero el análisis no era estructural. El siguiente análisis pretende demostrar cómo los miembros de una red personal ocupan más de un subgrupo relacional.
Sobre los 39 encuestados que mencionaron miembros que se solapaban entre diferentes tipos de cluster, había 6.4 miembros solapados por encuestado en promedio (con una desviación tipo de 4.7). Los miembros que pertenecen a varios clusters presentan algunas características que los distinguen de aquellos que no se solapan. Son significativamente mayores (.003) con un promedio de edad de 39 frente a 36, y han conocido al encuestado durante más tiempo (.001) que los que no se solapan (20 años frente a 12). Los miembros que pertenecen a varios clusters puntúan significativamente más alto en la escala de conocimiento que los que no se solapana (4.5 frente a 3.4).
La Tabla 6 aclara el predominio de las categorías familiares para los miembros que se solapan. En otras palabras, los miembros que tienden a existir en más de un tipo de cluster, también tienden a existir en algún tipo de cluster familiar. El predominio de la familia en el solapamiento es seguramente una función del predominio de los miembros de la familia en la lista de los encuestados y en el conjunto de los clusters. Mientras que el solapamiento entre clusters es algo frecuente, no está claro que ocurra con subgrupos que no son parecidos (tales como los cluster del trabajo y la religión).
|
Categoría 1 |
Categoría 2 |
Frecuencia |
|
Familia cercana |
Familia general |
16 |
|
Familia cercana |
Familia de la pareja |
15 |
|
Familia cercana |
Familia incluyendo amigos |
15 |
|
Familia cercana |
Red a través de tercero |
15 |
|
Familia general |
Familia incluyendo amigos |
12 |
|
Familia cercana |
Parejas |
11 |
|
Familia incluyendo amigos |
Red a través de tercero |
11 |
|
Familia general |
Familia de la pareja |
9 |
|
Familia cercana |
Trabajo anterior |
8 |
|
Familia general |
Red a través de tercero |
8 |
|
Familia general |
Grupo social |
8 |
|
Familia de la pareja |
Red a través de tercero |
8 |
Tabla 6. Frecuencia del solapamiento entre tipos de cluster
Recálculo de conglomerados
Estos resultados apuntan de modo intrigante hacia posibles reglas sobre cómo los subgrupos de la red se sostienen cognitivamente entre los individuos en Estados Unidos. Para una mejor comprobación se requiere de una muestra de encuestados más amplia y representativa. Sin embargo, el procedimiento para recoger estos datos conlleva mucho tiempo y esfuerzo (tanto por parte de los encuestados como de los entrevistados) para una aplicación más amplia. Si se pudiesen extraer resultados sustancialmente similares en una muestra mucho más pequeña, el método podría ser útil entonces en grandes encuestas de campo, o incluso en las entrevistas telefónicas.
En retrospectiva, algunos de los detalles sobre los miembros de la red no eran necesarios para categorizar los clusters. Dichos detalles podrían eliminarse en una encuesta telefónica o de campo, reduciendo el tiempo que conlleva el procedimiento. El verdadero ahorro de tiempo vendría de reducir el número total de miembros de la red implicados en el proceso.
Repetimos el análisis de conglomerados con los datos de cinco encuestados utilizando los primeros 50, 40, 30 y 20 miembros que habían mencionado en sus listas libres. Con los cinco encuestados se podían generar algunos clusters con 30 miembros o más. Ni el número de clusters ni el número de tipo de clusters se vio reducido de manera consistente con listas más cortas. De hecho, en uno de los casos el número de clusters aumentó.
De mayor interés son dos indicadores que ponderan la capacidad de los conjuntos reducidos de miembros para replicar el número y el tipo de clusters que se obtienen utilizando los 60 miembros –presumiblemente una representación más fiable del total de la red. Estos indicadores son el número de clusters válidos dividido por el número de miembros de la red y el número de tipos de cluster dividido por el número de miembros de la red. En cuatro de los cinco casos ambos indicadores alcanzaron el máximo nivel con 30 miembros, lo cual sugiere que 30 es un número óptimo de miembros de la red para la identificación de conglomerados. Limitando el procedimiento a una lista de 30 miembros se reduciría la extensión en más de la mitad, puesto que la generación de la matriz por parte del encuestado consistiría en evaluaciones sobre 435 parejas en lugar de 1.770.
Sin embargo, la tendencia hacia efectos de orden asociados con las listas libres sugieren que un subconjunto de miembros debería ser seleccionado aleatoriamente de una lista libre más amplia (Brewer, 2000). Una versión más corta del instrumento consistiría en pedir que los encuestados hagan una lista libre de 60 miembros, seleccionar a continuación 30 de los 60 miembros de la lista y seguir con la recolección de datos en este conjunto reducido.
Estudios de caso
El análisis anterior muestra que los encuestados reconocen agrupamientos de sus miembros que no son necesariamente intuitivos y que podrían dar lugar a una lista de miembros diferente de los habituales en un generador de nombres. Las categorías enumeradas más arriba son generalizaciones subjetivas de algunos agrupamientos muy específicos realizados por los encuestados. Los siguientes gráficos de los escalamientos multidimensionales de las matrices de adyacencia de cuatro encuestados, que ellos mismos ayudaron a categorizar, le dan credibilidad al etiquetado subjetivo y demuestran el potencial de este tipo de análisis. Con fines orientativos, Ego fue incorporado en las matrices de proximidad para el procedimiento MDS.
Steve
La historia de caso de Steve ilustra los efectos de la localidad en la formación y el mantenimiento de subgrupos. Originalmente de Australia, Steve cursó un MBA en Toronto (Canadá) y, en el momento de la recolección de datos, estaba trabajando en un doctorado en la Universidad de Florida. Steve mantenía contacto con su cohorte de graduados y con los miembros de la facultad y pertenecía a varios grupos de Hobby (véase Figura 1).

Los miembros de la lista de Steve son más similares en nivel educativo de lo que lo son los miembros de otras listas, y Steve mencionó más mujeres que el promedio citado por otros hombres encuestados (un 52% frente a un 43%). Una de las cuestiones que le pregunté a los encuestados sobre cada uno de los miembros mencionados era si el cambio de localidad interrumpiría la relación en el plazo de un año. En promedio, los encuestados dijeron que el 29% de sus miembros desaparecerían de la red ante tales circunstancias. Steve dijo que sólo 3 de sus 60 miembros (5%) desaparecería de la lista si no los viera durante un año.
Los tres indicadores de centralidad de Steve están por debajo del promedio, mostrando una menor cohesión estructural que otros encuestados. Con 13.03, su puntuación de intermediación (betweeness) está entre las más bajas de los 46 encuestados, indicando la ausencia de puentes entre los subgrupos de su red. Steve es uno de los pocos encuestados que tiene un alter diferente como el más central en cada una de las tres puntuaciones de centralidad. El alter con mayor puntuación en betweeness es un amigo que lo ha acompañado en su viaje desde Toronto, donde era un estudiante de un MBA, a Gainesville (Florida) donde es un estudiante graduado. Esto proporciona uno de los pocos lazos entre los diferentes subgrupos de Steve.
Steve generó más conglomerados que la mayoría de los encuestaods; 12 clusters, comparados con un promedio de 10. También generó más tipos de clusters que el promedio, con 7 comparados con 6.3. Estos niveles más altos se explican por la historia de vivir en muchos lugares combinada con una activa vida social.
Los tipos de cluster de Steve muestran su implicación en un programa de doctorado. De los 7 tipos de cluster utilizados, 5 correspondían a la universidad. Por otro lado, no dispone de conglomerados de familia cercana. Steve no tiene un núcleo duro de miembros familiares. Steve afirma que su madre es un punto central para él, su hermano y su hermana, pero son pocas las ocasiones en las que varios miembros de la familia se reúnen. La fuerte presencia de grupos sociales y de hobby es sólo la segunda detrás del alto número de grupos relacionados con la universidad.
Este reflejo de grupos dispersos y no relacionados es quizás más evidente en el área del solapamiento. Steve está por debajo del promedio, con sólo 2 de 60 miembros cruzando entre tipos de clusters, en comparación con 6.4 (con una desviación tipo de 4.7) para el conjunto de los encuestados. Esto se ajusta a su estrategia social, muy activa, moviéndose de un lugar a otro, de un grupo a otro, manteniendo núcleos de los miembros del grupo.
Betty
A diferencia de Steve, que es blanco, hombre y muy móvil, Betty es una mujer negra, secretaría en la universidad, con estudios secundarios y lazos fuertes con su localidad de origen. A diferencia de Steve, que ha viajado mucho, Betty raramente ha salido de Florida y Georgia. Tiene un fuerte sentido de pertenencia a esta área y lazos de familia cercana.
Betty mantiene su vida privada separada del trabajo. Cuando no está en el trabajo prefiere socializarse con la familia y sólo raramente participa en actividades sociales con los compañeros de trabajo. Con frecuencia visita a su familia en Georgia.
Betty menciona más mujeres que hombres en su red (el 62% y el 38%, respectivamente), bastante por encima del 54% mencionado por las mujeres encuestadas, en promedio. En términos de mantenimiento de relaciones, Betty no tiene ejemplos de relaciones situacionales, una diferencia significativa respecto al promedio del grupo (.001).
El nivel de conocimiento promedio fue significativamente más alto que el promedio respecto a los 2.820 miembros, con 4.1 frente a 3.5 (.001). Curiosamente, dice que perdería contacto con un porcentaje más alto del promedio en caso de mudarse. Betty tiene relaciones dependientes de la ubicación.
Betty tiene las puntuaciones más bajas en cercanía (closeness) e intermediación (betweeness) de todos los encuestados. Esto refleja el hecho de que la mayor parte de su red está compuesta de dos grandes grupos (trabajo y familia) con mucha conectividad interna, pero que apenas tienen conexiones entre sí.
Betty tiene un total de 12 clusters y 7 tipos de clusters. Su trabajo actual da cuenta de la mitad de los conglomerados, mientras que la familia cercana da cuenta de dos. Ella no incluye a su marido en la lista, pese al importante papel que juega en su vida. Esto muestra de nuevo los posibles problemas asociados con una lista libre.
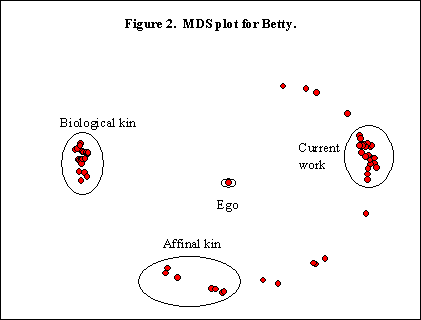
A diferencia de Steve, Betty tiene un alto grado de solapamiento entre clusters, y entre tipos de clusters. En su mayor parte dependen del solapamiento del trabajo y grupos sociales. La Figura 2 demuestra la importancia de las relaciones laborales en la lista de 60 miembros de Betty. En el lado derecho del dibujo predomina su trabajo actual. A la izquierda está su familia, que no comparte lazos con su trabajo, y la familia política está abajo, también separada de la familia biológica.
Tony y Mary
Tony y Mary se conocieron en el instituto, salieron durante muchos años, y se casaron al terminar los estudios universitarios. Se mudaron a Orlando al terminar la carrera y trabajaron como pareja de doble ingreso durante varios años. Los dos tienen familia en una ciudad muy cercana a Orlando y tienen varios grupos, con frecuencia parejas, con los que socializan. Mary fue aceptada en el servicio de odontología de la Universidad de Florida, y volvieron a Gainesville donde Tony fue admitido en un puesto en la Universidad.
La escuela de odontología es muy exigente, especialmente en los primeros años. Las entre 12 y 16 horas de Mary en el trabajo le dajan poco tiempo (u oportunidad) para el establecimiento de relaciones fuera de la rutina de la escuela de odontología. Esto le deja menos tiempo para socializarse con Tony.
Como Steve, Tony es una persona gregaria que se divierte socializándose con otros. Cuando Mary estaba disponible pasaba su tiempo con ella. Debido a sus obligaciones con las organizaciones de odontología, él la acompañaba en muchas actividades. Tony también ha desarrollado varias actividades sociales independientes de Mary.
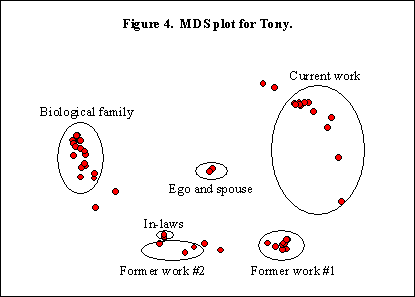
Tony tiene cuatro componentes, dos veces el promedio de los 46 encuestados. Como Steve, Tony tiene a mantener las relaciones con sus alteri incluso cuando se desplaza. Esto da lugar a subgrupos con poca o ninguna conexión, tales como la familia en Kentucky y sus antiguos compañeros de trabajo en Orlando. También se obtienen como resultado unos indicadores de centralidad no intuitivos, tales como el hecho de que el alter con más rango y más cercanía es la esposa de su tío. Esto demuestra los problemas de los indicadores basados en grafos que no pueden incorporar la fuerza del lazo, inflando en consecuencia la posición particular de un alter.
Mary divide los miembros de sus red en dos partes, exactamente la mitad son hombres y la otra mitad mujeres, lo cual supone un porcentaje mucho más elevado de hombres de lo que es habitual entre las mujeres encuestadas. Esto se debe sin duda a la alta proporción de hombres en su cohorte de la escuela de odontología.
Las puntuaciones de rango y cercanía de Mary son mucho más altas que el promedio, reflejando de nuevo su inmersión en el programa dental donde la mayoría de los estudiantes se conocen entre sí. Como hay pocos puentes que hacer, su puntuación en betweeness está por debajo del promedio con 19.54. Su alter con mayor rango y cercanía es un miembro de la facultad del programa de odontología.
Con seis clusters, Mary está una desviación tipo por debajo del promedio del grupo. El predominio del cluster de odontología explica el 69% de la varianza total en el análisis de conglomerados. Apenas hay lugar para la expresión de otras agrupaciones puesto que el cluster de odontología da cuenta aproximadamente de la mitad de los miembros de Mary y existe un alto grado de conocimiento mutuo en dicho cluster. Su único cluster familiar es una mezcla de familia cercana y distante, sin un núcleo muy unido.
Tony está muy cerca del promedio del grupo en muchas características de su red. No tiene muchos casos en los que alguien mantiene la relación, sino significativamente más incidencia de las relaciones situacionales (.001), más del doble del promedio. Tiene lazos familiares fuertes y también una representación fuerte del trabajo actual y del trabajo anterior. De hecho, parece que en cualquier lugar en el que Tony trabaja conoce a gente que mantiene como un subgrupo. Probablemente sean grupos sociales en los que ha estado implicado durante muchos años.
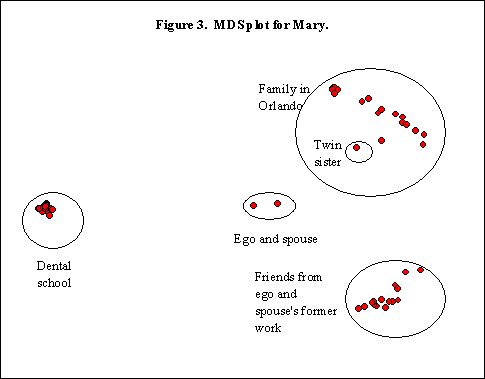
Los gráficos del MDS de Mary y Tony son interesantes (véanse las Figuras 3 y 4). En ambos gráficos los dos son el miembro más cercano para el otro. En el gráfico de Mary se distinguen fácilmente el cluster de odontología con el 40% de los miembros de su red, el agrupamiento de Orlando y el agrupamiento de los compañeros de trabajo. Pese a que ella está muy incrustada en el cluster de odontología, sus relaciones con los otros clusters implican a Tony. De hecho, Tony está integrado en el conglomerado de odontología gracias a su asistencia a muchas actividades sociales de los profesionales sanitarios en las que se anima a que participe el esposo. Del mismo modo, los conglomerados de Tony de la familia, el trabajo actual y el trabajo anterior son equidistantes respecto a él, con Mary en el centro. Ella también es miembro de los clusters, en gran medida a través de él.
Discusión
Este estudio demuestra el potencial de analizar los aspectos estructurales de las redes personales. No es original en términos conceptuales, puesto que otros han examinado la densidad del núcleo de la red. Pese a que el listado libre de los miembros de la red presenta algún problema con la memoria y la exclusión de lazos débiles (Brewer, 2000), aumentar la lista de miembros hasta 60 (frente a la práctica habitual de entre 5 y 10 miembros) arroja una muestra más representativa del total de la red personal. Otros han sugerido que al incluir lazos más distantes pueden emerger fenómenos estructurales que explican el comportamiento del encuestado en diversas áreas, especialmente en intercambios de apoyo social (Milardo, 1989; Walker, Wasserman & Wellman, 1993).
Está claro a partir de estos datos que los indicadores de estructura basados en grafos varían entre encuestados. Una interpretación de dicha variabilidad es que refleja las estrategias de los encuestados en términos de compartimentalización de sus redes e inversión de tiempo. Con una muestra más heterogénea y la inclusión de indicadores adicionales, el análisis de estos indicadores estructurales podría ser útil para predecir atributos de los encuestados, tales como las puntuaciones en un inventario de personalidad o en una escala de depresión.
Muchas de las categorías que emergen de este análisis no son sorprendentes. Por ejemplo, espero encontrar que la gente clasifique de forma natural a los miembros de su red en familia, vecinos, gente que conocen del trabajo, gente con la que fueron (o con la que van) a estudiar, y gente con la que comparten un hobby. De hecho, me mostraría escéptico de no encontrar dichos resultados.
Por otro lado, el 42% de los encuestados distingue entre gente que conocen de su trabajo actual y gente que conocen de algún trabajo anterior; el 25% de los miembros fueron mencionados porque pertenecían a la red de los encuestados a través de intermediarios. Ninguno de estos dos hallazgos es intuitivo, pero es precisamente gracias a los resultados intuitivos que tengo confianza en los que son sorprendentes.
Revisiones previas de este trabajo han sugerido que el análisis estructural de las redes personales no nos dice mucho más sobre un encuestado de lo que podríamos obtener haciéndole preguntas cualitativas generales sobre la gente a la que conoce. ¿Serviría dicha entrevista para encontrar una correlación negativa entre la familia cercana y las agrupaciones relacionadas con hobbies? ¿Encontraría que los conglomerados de miembros de la red vinculados con un intermediario concreto son tan prevalentes como parecen ser?
Es improbable que las personas hagan dichas evaluaciones de su red cualitativamente. Las tendencias de otras características estructurales de las que no informo en este artículo, tales como centralidad y densidad, serían prácticamente imposible de detectar sin un análisis sistemático como este. Realmente con estos datos se pueden hacer más análisis, y se harán, que complementan lo que se puede aprender simplemente hablando con alguien sobre las personas a las que conoce.
Los estudios de caso traen a colación una aplicación práctica del método. Podemos imaginar a un terapeuta utilizando los dibujos del MDS, los conglomerados y los datos relacionales como un vehículo para analizar la “salud” de la red de apoyo de un cliente. Esto supone asumir que hay algunas propiedades de las redes de apoyo social que pueden ser concebidas como saludables o perniciosas. Algunos estudios ya han sugerido que la satisfacción del cliente se relaciona con la existencia de confidentes (Conner, Powers & Bultena, 1979), ciertos niveles de densidad (Hirsch, 1979, 1980), o el tamaño de la red (Polister, 1980).
Finalmente, este estudio ha mostrado cómo las matrices de redes personales generadas con diferentes encuestados pueden analizarse de manera transversal (con diferentes individuos) para revelar algunas características de las redes personales que habían sido ignoradas hasta ahora. El hecho de que los tipos de cluster fuesen verificados de forma independiente con una muestra de encuestados demuestra la validez de las evaluaciones de lazos entre redes. He mostrado que las características de la red derivadas de las matrices pueden resumirse de modo transversal entre los encuestados para mostrar las tendencias en la composición de la red.
Lo que separa a este artículo de otros estudios sobre las redes personales no es más que el tiempo y el esfuerzo extra de preguntar a los encuestados sobre las relaciones entre todas las parejas potenciales en una red personal amplia. Mientras que esto es tedioso para los encuestados, los programas informáticos pueden facilitar la tarea aprovechando los patrones que emergen cuando el encuestado evalúa parejas. El desarrollo de dicho software dedicado al análisis estructural de las redes personales y a la agregación de las redes de los encuestados sería una potente herramienta.
Referencias
Arabie, P., J. D. Carroll, W. DeSarbo and J. Wind (1981), “Overlapping Clustering: A New Method for Product Positioning,” Journal of Marketing Research 18: 310-317.
Beggs, J. J., V. A. Haines and J. S. Hurlbert (1996), “Situational Contingencies Surrounding the Receipt of Informal Support,” Social Forces 75: 201-222.
Bernard, H. R., P. D. Killworth, M. J. Evans, C. McCarty and G. A. Shelley (1988), “Studying Social Relations Cross-Culturally,” Ethnology 27: 155-179.
Bernard, H. R., P. D. Killworth, C. McCarty and G. A. Shelley (1990), “Comparing Four Different Methods for Measuring Personal Social Networks,” Social Networks 12: 179-215.
Borgatti, Stephen P. (1997), “Structural Holes: Unpacking Burt’s Redundancy Measure,” Connections 20: 35-38.
Brewer, D. D. (2000), “Forgetting in the Recall-based Elicitation of Personal and Social Networks,” Social Networks 22: 29-43.
Burt, R. (1982), Toward a Structural Theory of Action: Network Models of Social Structure, Perception, and Action , New York: Academic Press .
Burt, R. (1984), “Network Items and the General Social Survey,” Social Networks 6: 293-339.
Burt, Ronald S. (1992), Structural Holes (Cambridge: Harvard University Press).
Burt, Ronald S., Joseph E. Jannotta and James T. Mahoney (1998), “Personality Correlates of Structural Holes,” Social Networks 20: 63-87.
Campbell, K. E. and B. A. Lee (1991), “Name Generators in Surveys of Personal Networks,” Social Networks 13: 203-221.
Conner, K. A., E. A. Powers and G. L. Bultena (1979), “Social Interaction and Life Satisfaction: An Empirical Assessment of Late-life Patterns,” Journal of Gerontology 34: 116-21.
Fischer, C. S. (1982), To Dwell Among Friends (Chicago: University of Chicago Press).
Frank, O. (1978), “Sampling And Estimation in Large Social Networks,” Social Networks 1: 91-101.
Freeman, Linton (1979), “Centrality in Social Networks: I. Conceptual Clarification,” Social Networks 1: 215-39.
Galaskiewicz, J. and P. Marsden (1978), “Interorganizational Resource Networks: Formal Patterns of Overlap,” Social Science Research 46: 89-107.
Gerlach, Michael L. (1992), “The Japanese Corporate Network: A Blockmodel Analysis,” Administrative Science Quarterly 37: 105-34.
Gottlieb, B. H. (1981), “Preventive Interventions Involving Social Networks and Social Support” in Social Networks and Social Support , edited by B. H. Gottlieb (Newbury Park, CA: Sage).
Hirsch, B. J. (1979), “Psychological Dimensions of Social Networks: A Multidimensional Analysis,” American Journal of Community Psychology 7: 263-78.
Hirsch, B. J. (1980), “Natural Support Systems and Coping with Major Life Change,” American Journal of Community Psychology 8: 159-72.
Krackhardt, David (1999), “The Ties That Torture: Simmelian Tie Analysis in Organizations,” Research in the Sociology of Organizations 16: 183-210.
Marsden, P. V. and K. E. Campbell (1984), “Measuring Tie Strength,” Social Forces 63: 483-501.
Marsden, P. V. (1990), “Network Data and Measurement,” Annual Review of Sociology 16: 435-63.
Mayhew, Bruce (1981), “Structuralism vs. Individualism: Part I, Shadowboxing in the Dark,” Social Forces 59: 335-375.
McCarty, C. (1996), “The Meaning of Knowing as a Network Tie,” Connections 18: 20-31.
McCarty, C., H. R. Bernard, P. D. Killworth, E. C. Johnsen and G. A. Shelley (1997), “Eliciting Representative Samples of Personal Networks.” Social Networks 19: 303-323.
Milardo, Robert M. (1989), “Theoretical and Methodological Issues in the Identification of the Social Networks of Spouses,” Journal of Marriage and the Family 51: 165-174.
Mitchell, Clyde (1994), “Situational Analysis and Social Networks,” Connections 17: 16-22.
Myers, G. P., G. A. McGrady, C. Marrow and C. W. Mueller (1997), “Weapon Carrying Among Black Adolescents: A Social Network Perspective.” American Journal of Public Health 87: 1038-1040.
Neaigus, Alan, Samuel R. Friedman, Richard Curtis, Don C. Des Jarlais, R. Terry Furst, Benny Jose, Patrice Mota, Bruce Stepherson, Meryl Sufian, Thomas Ward and Jerome W. Wright (1994), “The Relevance of Drug Injectors’ Social and Risk Networks for Understanding and Preventing HIV Infection,” Social Science and Medicine 38: 67-78.
Nieuwbeerta, P. and Henk Flap (2000), “Crosscutting Social Circles and Political Choice: Effects of Personal Network Composition on Voting Behavior in The Netherlands,” Social Networks 22: 313-335.
Padgett, John F. and Christopher K. Ansell (1993), “Robust Action and the Rise of the Medici, 1400-1434,” American Journal of Sociology 98: 1259-1319.
Polister, P. E. (1980), “Network Analysis and the Logic of Social Support” in Evaluation and Action in the Environment , edited by R. H. Price and P. E. Polister (New York: Academic Press)
Raider, Holly J. (1998),”Market Structure and Innovation,” Social Science Research 27: 1-20.
Spreen, M. (1992), “Rare Populations, Hidden Populations, and Link-Tracing Designs: What and Why?” Bulletin de Methodologie Sociologique 36: 34-58.
Spreen, M. and R. Zwaagstra (1994), “Personal Network Sampling, Outdegree Analysis and Multilevel Analysis: Introducing the Network Concept in Studies of Hidden Populations,” International Sociology 9: 475-491.
Spreen, M. (1999), Sampling Personal Network Structures: Statistical Inference in Ego-Graphs , unpublished dissertation, University of Groningen.
Walker, Michael E., Stanley Wasserman and Barry Wellman (1993), “Statistical Models for Social Support Networks,” Sociological Methods and Research 22: 71-98.
Wellman, B. (1979), “The Community Question: The Intimate Networks of East Yorkers,” American Journal of Sociology 84: 1201-1231.
Wellman, B. (1981), “Applying Network Analysis to the Study of Social Support” in Social Networks and Social Support , edited by B.H. Gottlieb (Newbury Park, CA: Sage).
Wellman, B. and S. Wortley (1990), “Different Strokes from Different Folks: Community Ties and Social Support,” American Journal of Sociology 96: 558-588.