Actualmente se disponen de algoritmos (algunos de ellos implementados en Ucinet 6) que permiten identificar "comunidades". Los artículos de referencia son:
* Girvan, Michelle & Newman, M.E.J. (2001). "Community structure in social and biological networks" <http://aps.arxiv.org/abs/cond-mat/0112110/> (ver también la página de Newman <http://www-personal.umich.edu/~mejn/recentpubs.html>)
* Guimerà R. Danon, L.; Díaz-Guilera A.; Giralt, F; Arenas, A. et. al. (2002). "The real communication network behind the formal chart: community structure in organizations", 7th Granada Seminaron Computational and Statistical Physics (Granada, Spain, 2-7 September). [pdf]
Realizaremos un análisis a partir de la red constituida por los mensajes de la lista REDES en tres períodos diferentes. En esta página se puede encontrar una descripción de cómo se han obtenido los datos. El primer período es de Abril 2000 a Febrero de 2002, el segundo período va de Marzo de 2002 a Junio de 2002 y el tercero de Julio de 2002 a Julio de 2003. Los ficheros tienen formato DL.
período 1DL
período 2DL
período 3DL
Entre el primer y el segudo período se informó a los miembros de la lista de su posición en la red. Nuestra hipótesis fue que al poner un grupo delante de un espejo se producía un fenómeno de institucionalización ... pero esto es solamente una idea ...
Paso 1: Preparar Ucinet 6-Netdraw y los ficheros de datos
Obviamente (repetimos) hay que disponer de Ucinet 6 y Netdraw (www.analytictech.com). Una vez carguemos Ucinet 6 escogeremos File>Change default folder y eligiremos un subdirectorio, por ejemplo, "Cops". En este subdirectorio descargaremos los dos ficheros DL ("periodo 1.txt" y "periodo 2.txt"). ¿Listo? Pues adelante. Hay que tener cuidado que los ficheros de texto tengan saltos de línea (hay en la práctica múltiples formatos de texto por desgracia). Si aparecen todos los caracteres seguidos intentad abir el fichero con WordPad o Word y guardadlo como texto. El formato correcto de "periodo 2.txt" es:
dl
n = 40 format = el1
labels
embedded
data:
federico
isidromj 1
adochao
isidromj 1
manisero1
iogz4 1
erralde2
iogz4 1
amparolafc
isidromj 1
...
Una vez tengais preparados los ficheros en Ucinet elegir Data>Import>DL e importad el primer fichero. Haced lo mismo con el segundo fichero. De esta forma se crearán en el subdirectorio "Coops" los ficheros de Ucinet
Obtendremos la siguiente pantalla:
Si clicamos el símbolo amarillo del rayo on un "=" (el icono a la izquierda de L) obtendremos la siguiente pantalla:
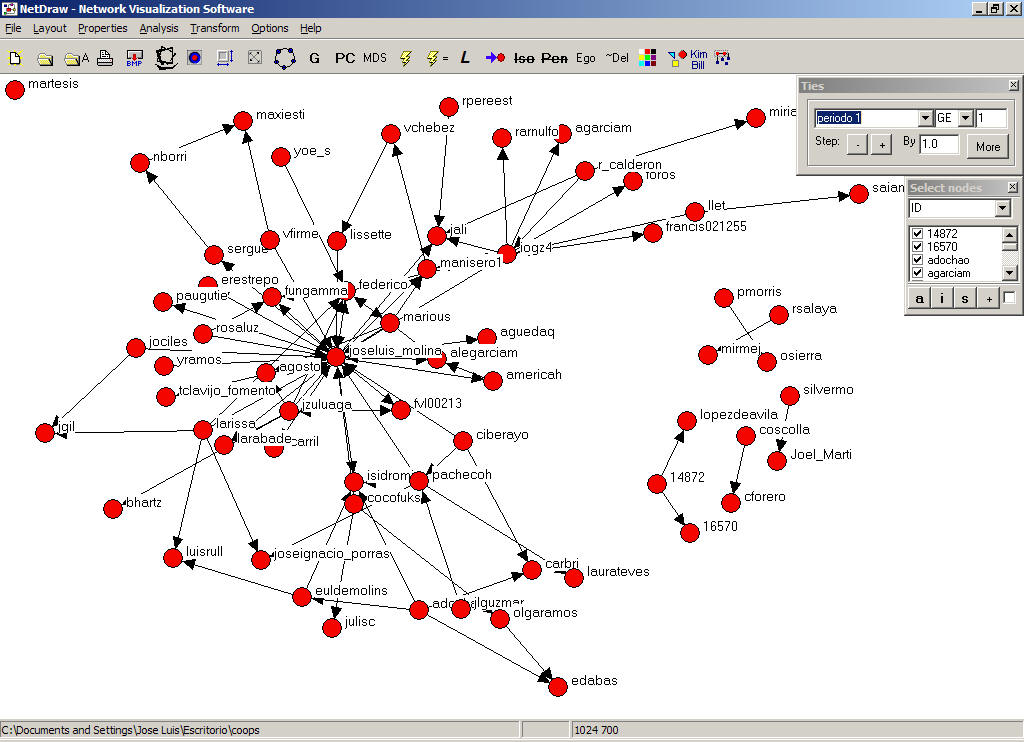
Escojamos ahora Analysis>Subgroups>Newman-Girvan y obtendremos una ventana de diálogo que nos pregunta el número mínimo y máximo de grupos a identificar. Escogemos 2 y 5 respectivamente y obtenemos lo siguiente (además de un largo mensaje que explicaremos más adelante).
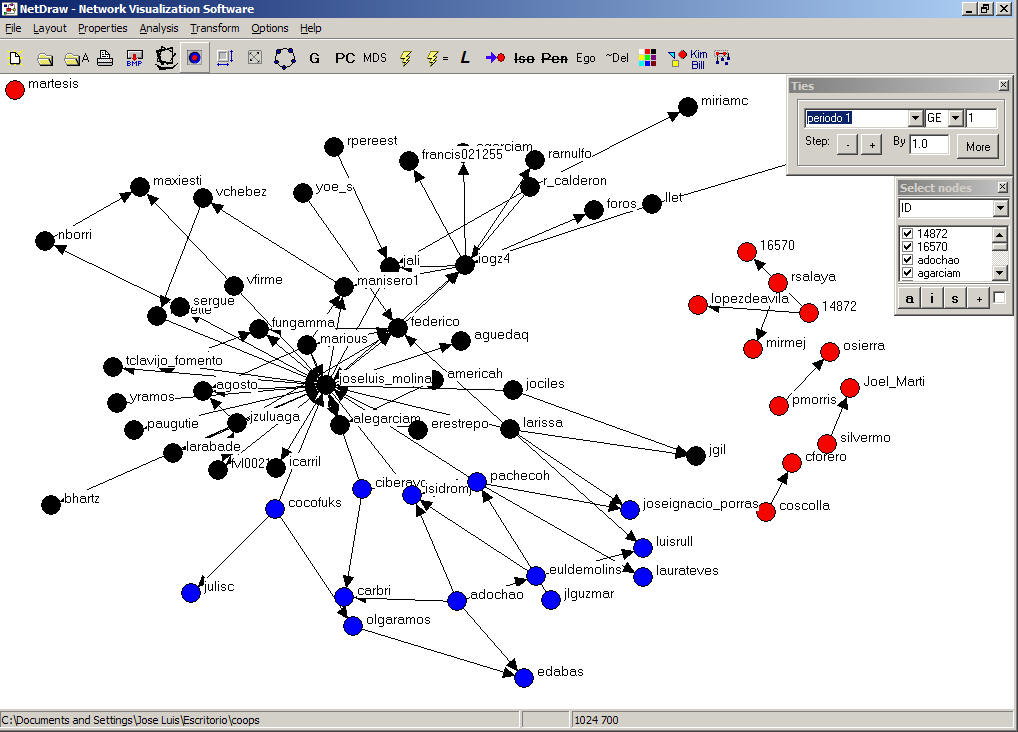
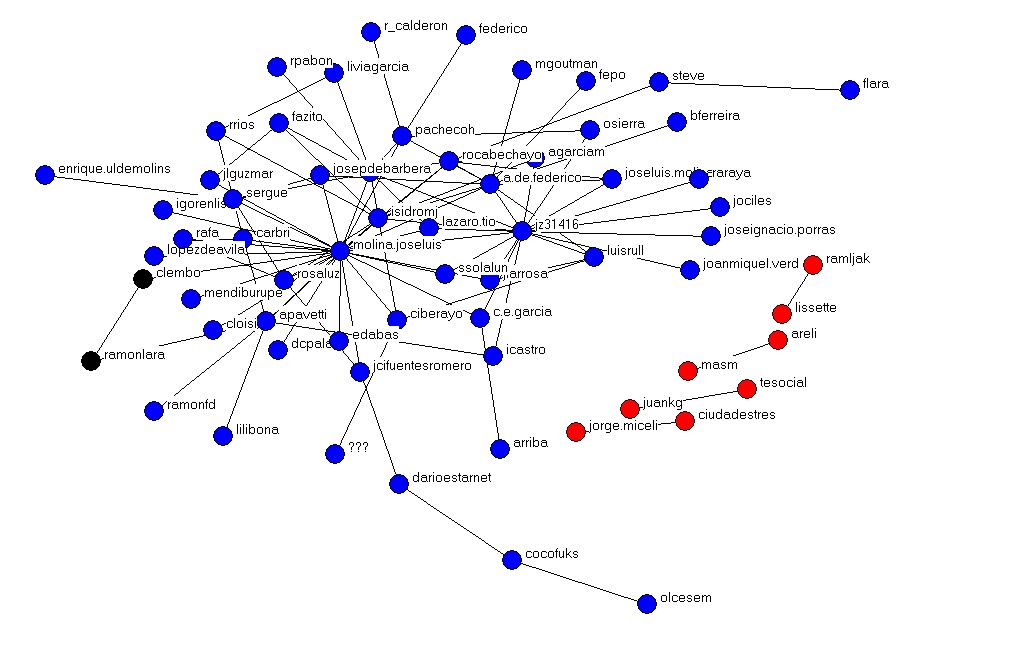
Una caña ¿no? Se supone que hemos hecho una primera identificación de los subgrupos a través de los cuales circularía el "conocimiento" ... ¿Está ya? Pues seguimos ...
En el gráfico anterior se observan tres colores: rojo, negro y azul. Sin embargo, podemos ir aumentando el número de subgrupos en el análisis. Para ello clicaremos el cuadro con colores a la derecha de ~Del y en el menú desplegable seleccionaremos la partición que más nos interese.
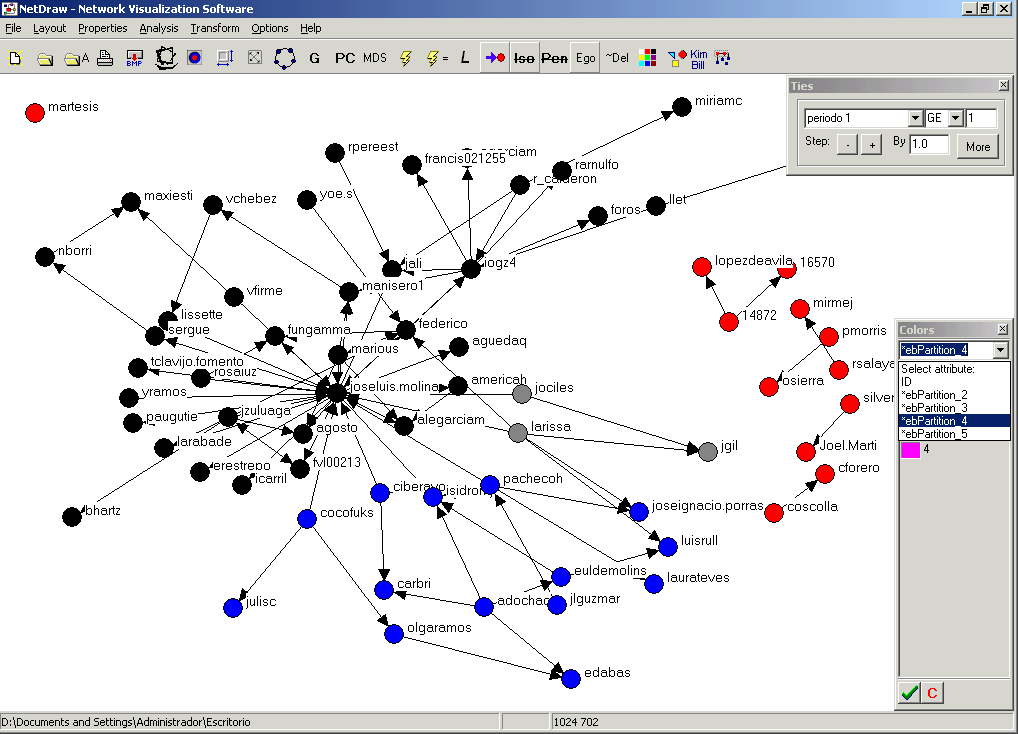
Veréis que no hay muchos cambios. Veamos qué pasa en el período 2. Pues lo siguiente (he quitado las cabezas de las flechas clicando encima del botón con un punto rojo a la derecha de L.
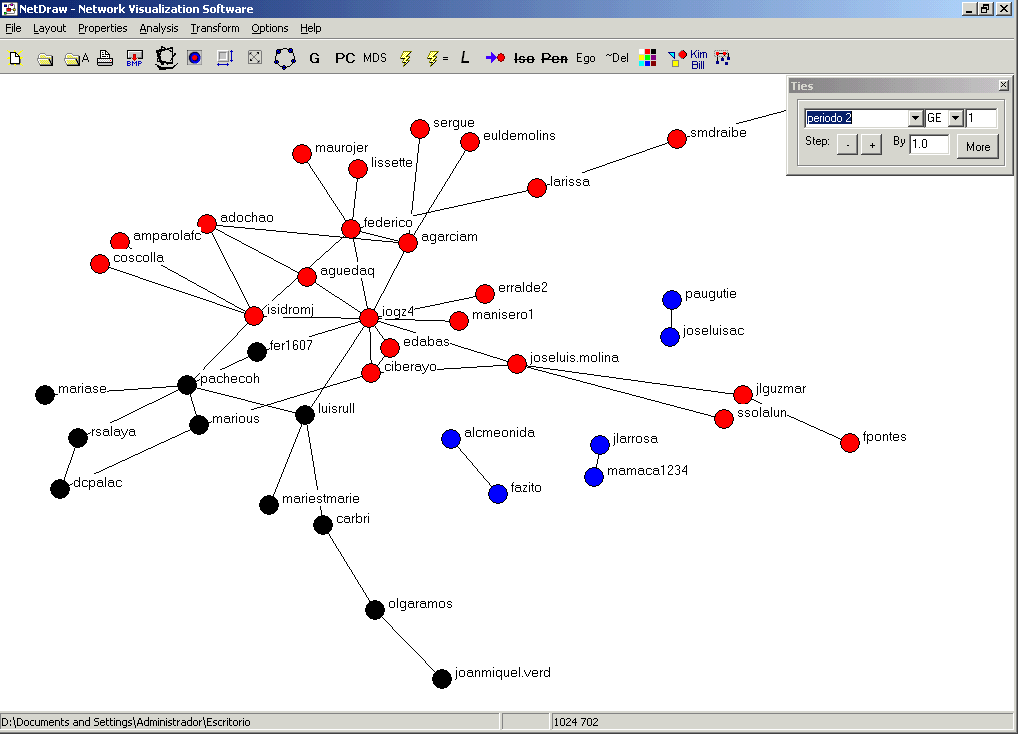
Je,je, está claro que las centralidades de algunos nodos cambian en el período 2 ... pero ¿cambian las "comunidades de aprendizaje"? Decídmelo vosotros.
Observemos ahora las "comunidades de aprendizaje" en el tercer período. ¿Podemos decir que hay una gran "comunidad" con diferentes nodos activos? Da la impresión que a lo largo del tiempo la lista REDES se va haciendo más homogénea, con más nodos dentro del grupo principal y con diferentes nodos activos ... Ahora por supuesto se trataría de hacer un análisis comparativo en profundidad, por ejemplo de nodos x COPs y ver su evolución a lo largo del tiempo. También deberíamos tener en cuenta otros datos como son la variables sociométricas clásicas y el tráfico privado entre esos mismos miembros de la lista que, evidentemente, no se ha podido recoger aquí. Pero es un comienzo ¿no?